
Cet article a été écrit par le Data Studio de Foyer, juste avant le confinement en France le 16 mars 2020.
Les compagnies d’assurance disposent d’une data quantité importante de données à propos de leurs clients. Grâce à l’émergence du Machine Learning et du Deep Learning, ces compagnies sont en mesure d’extraire de ces données de l’information, dans le but d’offrir de meilleurs services. C’est dans cette optique que Foyer a créé le Data Studio en 2017.
L’épidémie Covid-19 est apparue en Chine en janvier 2020. Le nombre de personnes infectées et le bilan humain à travers le monde sont dramatiques. Afin de ralentir l’épidémie, certains gouvernements ont décidé d’imposer le confinement à leurs citoyens pendant quelques semaines, afin de limiter les interactions sociales qui sont le vecteur de propagation du virus. Nous avons essayé de modéliser le nombre de cas en France, afin de voir que notre simple modèle permettait de capter la tendance globale de l’épidémie, et pour souligner le fait que sans un changement de comportement, l’épidémie deviendrait hors de contrôle.
Nous ne prétendons pas être capables de prédire précisément le nombre futur de cas, nous ne sommes pas épidémiologistes. Nous utilisons un modèle mathématique appelé un processus de Hawkes (HP) afin de modéliser l’évolution de l’épidémie. Le principe d’un HP est qu’il s’agit d’un processus auto-excité. Cela signifie que chaque nouvelle infection « excite » le processus en augmentant la vitesse de propagation de l’épidémie (appelée intensité). C’est ce qu’il se passe pendant une pandémie : chaque nouveau cas pourrait transmettre le virus à d’autres personnes et ainsi causer de nouvelles infections.
Le modèle est appris sur les données observées jusqu’au 8 mars. Pour vérifier si notre modèle est correct, nous simulons l’évolution du 8 au 16 mars selon notre modèle, puis nous comparons dans le premier graphe le nombre de cas (N(t) dans la légende) pour le HP (en rouge, encadré par des courbes vertes représentant l’incertitude de la prédiction) avec les vraies données (en bleu). Le second graphe montre la différence en pourcentage entre les données simulées et réelles.
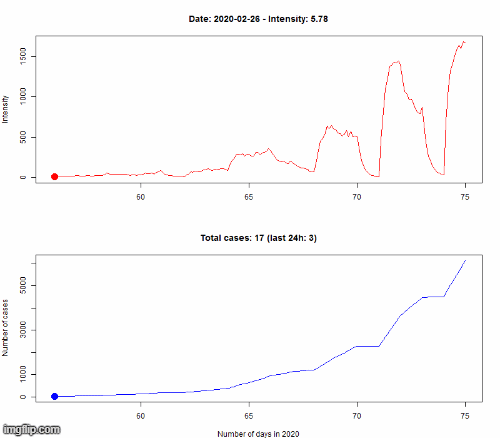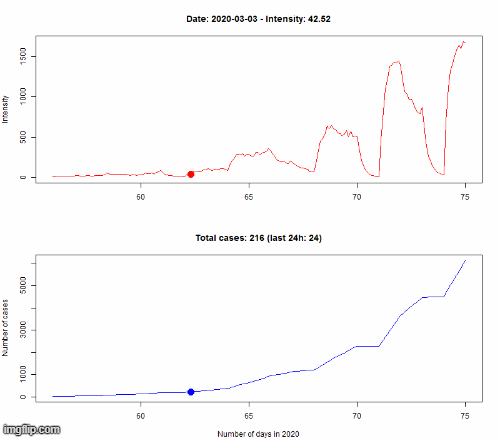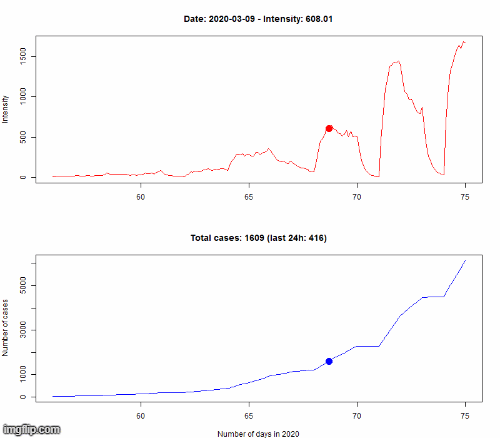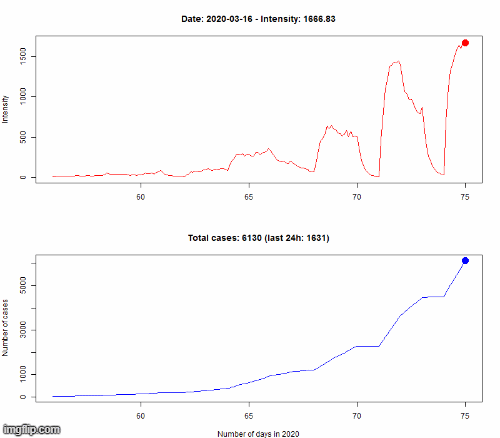
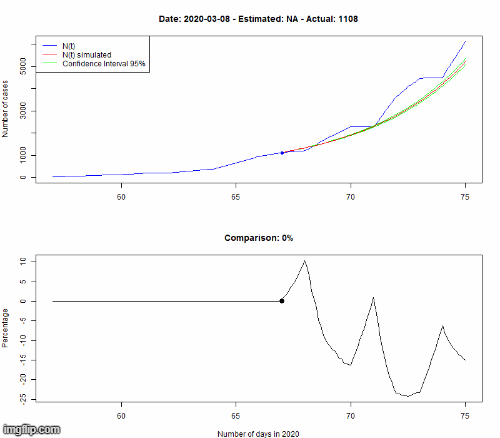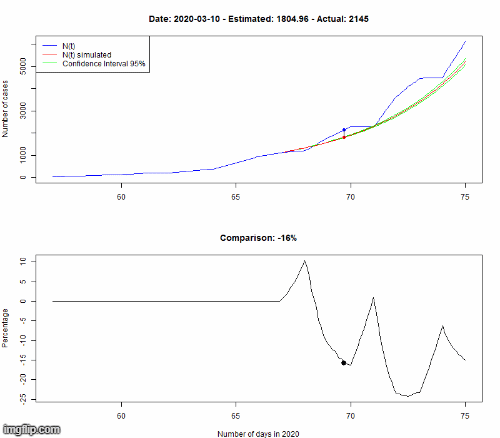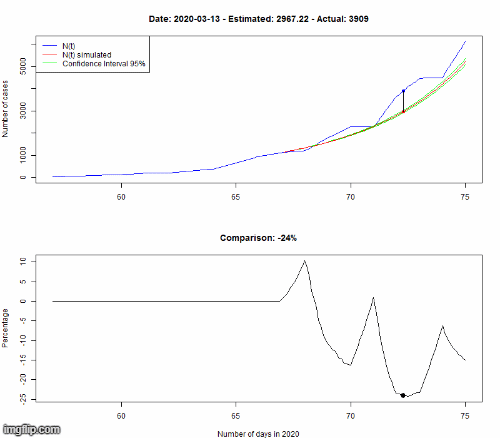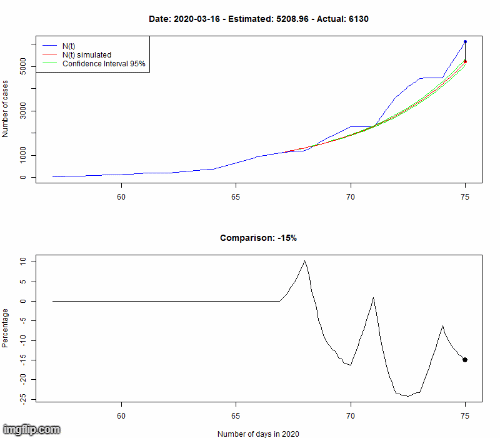
Même si cela n’est pas parfaitement précis, la dynamique d’évolution est bien captée par notre modèle, avec une croissance exponentielle du nombre d’infectés.
Après cela, nous simulons l’évolution du nombre d’infections sur 10 jours (jusqu’au 26 mars). Nous travaillons sur deux scénarios : soit la dynamique de l’épidémie reste la même, soit un confinement est respecté de la part des citoyens français, en modifiant notre modèle avec une baisse de l’intensité.
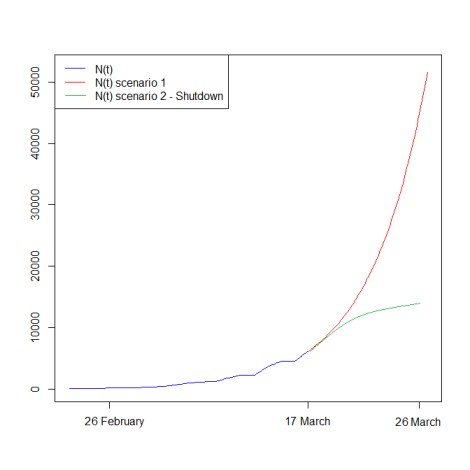
Le résultat montre que le confinement réduirait significativement le nombre de cas estimé. Nous obtenons un nombre de cas de 51,642 avec le premier scénario, contre 14,621 pour le second, environ trois fois moins ! Il est absolument nécessaire pour la population de respecter le confinement, les résultats de notre étude le montrent.
Plus globalement, l’analyse de données nous a permis de mieux comprendre un phénomène complexe tel que cette épidémie. Cela montre que les données peuvent apporter beaucoup d’informations avec une analyse appropriée.
